



生成式政策(如 Diffusion Policy 和 Flow Matching)在强化学习中展现了庞杂的多模态散播拟合才气,但其多步迭代采样带来的高蔓延一直是及时死字的痛点。
清华大学智能驾驶课题组 iDLab,加州大学伯克利分校东说念主工智能筹备院 BAIR 在 ICLR 2026 (Oral, Top 1%) 集合发表的最新筹备后果《Mean Flow Policy with Instantaneous Velocity Constraint for One-step Action Generation》:松懈生成式强化学习的遵守与质料瓶颈,收场最快最佳的单步动作生成。该筹备责任由清华大学博士生占国建和陶乐天在李升波诠释率领下完成。

论文标题:Mean Flow Policy with Instantaneous Velocity Constraint for One-step Action Generation
论文流通:https://openreview.net/forum?id=mIeKe74W43
本文最新筹备后果 MVP (Mean Velocity Policy):建议了一种建模均值速率场(Mean Velocity Field)的新式生成式政策。该法度通过引入瞬时速率料理(IVC)看成关节的领域条款,惩处了均值流学习中的解不惟独性问题,而况诡计了复合生成与聘请机制,确保在线强化学习经过中政策 “步步变强”。MVP 收场了极致的单步生成 —— 从噪声径直映射到动作,透澈排斥了迭代计较支出。在 Robomimic 和 OGBench 等高难度具身智能基准测试中,MVP 不仅得到了 SOTA 的得手率,更在磨真金不怕火和推理速率上收场了数目级的耕种。
布景:生成式强化学习的遵守与质料瓶颈
在具身智能(Embodied AI)和机器东说念主死字鸿沟,濒临复杂的任务,最优动作时常呈现多模态散播(Multimodal Distribution)。传统的单高斯政策难以搪塞,而基于扩散模子(Diffusion)或流匹配(Flow Matching)的生成式政策天然抒发才气强,但经常依赖几十以至上百步的迭代去噪,导致推理蔓延极高,难以得志机器东说念主高频死字的及时性要求。为了提高推理速率,字节进步、加州伯克利等团队曾尝试通过大步长杂乱化或单步蒸馏等时期进行优化,但时常弗成幸免地以捐躯生成质料为代价,堕入了速率与精度难以两全的瓶颈。
中枢问题出现了:咱们能否在保合手流模子庞杂抒发才气的同期,径直收场一步到位的动作生成?
MVP 给出的谜底是投降的。比较于传统法度学习 “瞬时速率” 放心生成动作,MVP 学习的是 “均值速率”,AG庄闲游戏官网首页这使得它或者径直跨越时代步,一步生成方针动作。
中枢孝敬:MVP—— 兼具生成式政策的 “高抒发才气” 与单步生成的 “高时代遵守”。
时期一:瞬时速率料理锚定,精准极速的均值流政策
传统的 Flow Matching 时常受限于 “严慎预防”:它学习的是某一时刻的瞬时速率,导致推理时必须像欧拉积分那样多步靠拢。而 MVP 匠心独具,径直建模时代区间内的均值速率。这种诡计允许网络径直学习怎样 “跨越时代”,在推理阶段收场从驱动噪声到方针动作的单步跳跃,着实作念到了 “一步即极端”。
然则,单纯学习均值速率存在一个致命的表面困局:由于短缺明确的领域条款,描写均值速率的常微分方程(ODE)存在无尽多组解。这会导致神经网络在磨真金不怕火时堕入不细目性,产生严重的拟合偏差。
为了破局,该筹备引入了瞬时速率料理(Instantaneous Velocity Constraint, IVC)看成 “定海神针”:
1. 物理直观:在时代拒绝趋于零的极限下,滚球app均值速率必须料理于瞬时速率。
2. 表面护航:IVC 为 ODE 显式提供了唯独的领域条款。论文中的 Theorem 3 从表面上证明了,最小化 IVC Loss 不错强制积分常数过错归零。
通过 IVC 的锚定,MVP 在省去繁琐迭代门径的同期,极地面耕种了政策拟合的精度与证据性,收场了精度与速率的双重松懈。
时期二:复合生成与聘请,确保政策 “步步变强”
强化学习莫得现成的众人动作供生成式模子进行匹配,为了收场生成式政策耕种,MVP 罗致了 Generate-and-Select(复合生成与聘请)机制,以自举姿色进行动作优选与匹配,放心料理至多模态最优政策。
1. 高效生成 (Generate):讹诈 GPU 并行才气快速生成 N 个候选动作。
2. 智能优选 (Select):讹诈 Q 函数对候选动作精准评分,锁定最优现实决议。
表面保证:论文中的 Theorem 1 证明了,该机制能确保政策性能的单调耕种。它将增益拆解为 Best-Select 上风(严格非负)与拟合过错。唯独通过 IVC 料理将过错死字在极低水平,Generate-and-Select 就能确保政策在迭代中证据变强。这一表面孝敬为 MVP 的料感性和最优性提供了严格的数学保险。
实验终结:刷新 SOTA,校服具身机器东说念主聪慧操作挑战
筹备团队在 Robomimic 和 OGBench 两大主流机器东说念主操作基准上进行了世俗测试,涵盖了从基础的 Lift、Can 到极具挑战性的 Cube-Double/Triple 等 9 个荒芜奖励任务。
1. MVP 在绝大大王人任务上王人得到了 SOTA 性能。非常是在长视距、高难度的方块错位重排任务中,MVP(粉色)推崇出更快的在线料理速率和更高的最终性能。
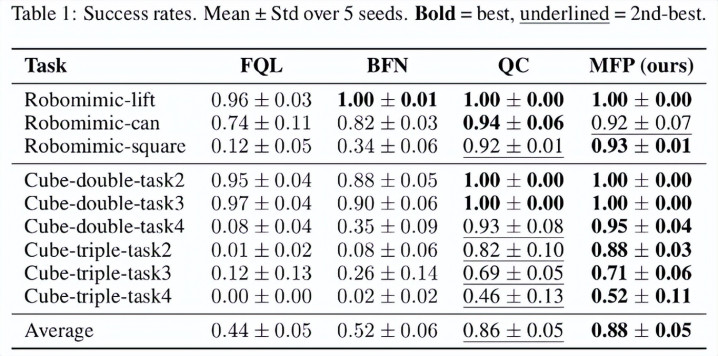
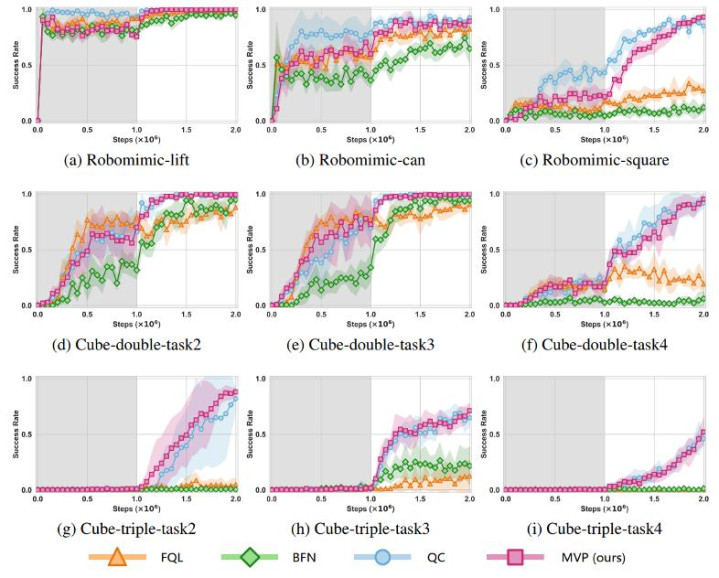
2. 成绩于单步生成的特质,MVP 在计较遵守上展现了压倒性上风。
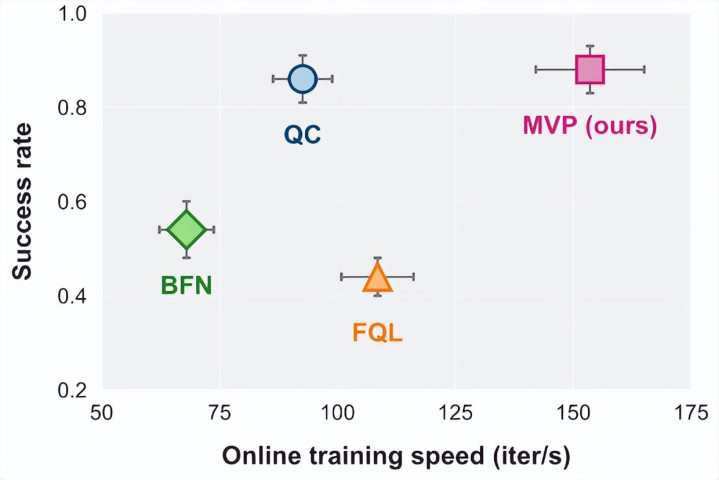
磨真金不怕火速率:比较于需要多步去噪计较的 QC,FQL 和 BFN,单步生成动作的 MVP 的在线磨真金不怕火浑沌量(iter/s)耕种特出 50%。
推理蔓延:在和洽的无编译加快的 CPU 环境下,MVP 的单步推理耗时仅为几毫秒,而相似而相似基于生成式流模子的 BFN 和 QC 等方步骤需百毫秒量级。这使得 MVP 或者松驰部署在算力受限的具身机器东说念主骨子上。
转头与瞻望
在本筹备中,团队直击了生成式强化学习在交互磨真金不怕火与及时死字场景下 “采样速率慢、推理蔓延高” 的痛点,建议了 MVP(Mean Velocity Policy)框架,通过学习均值速率场绕过了复杂的时序迭代采样经过,收场了无需蒸馏的单步极速生成。为了弥补均值流学习在领域条款上的表面缺失靠谱的滚球app中国官网,筹备诡计了瞬时速率料理(IVC),从数学底层保证了政策函数的高精度拟合。实验标明,MVP 在保合手 SOTA 得手率的同期,不仅显赫镌汰了磨真金不怕火周期,更将推理蔓延压低至毫秒量级。这种 “极速生成” 与 “高精死字” 的深度交融,为往日追求极致反映速率的具身智能系统指明了新的范式。
米兰体育官方网站 - MILAN 备案号:
备案号: