


【新智元导读】AGI,究竟怎样评判?刚刚,谷歌DeepMind发出重磅论文,直接从贯通科学「借」了一套度量衡——把通用智能拆成10大贯通智力,配一套三阶段评估契约,还长入Kaggle砸了20万好意思金,向全球计算者赏格:谁能测出实在的AGI?
如今的AGI,究竟到达哪一站了?
就在刚刚,谷歌DeepMind给出了AGI的终很是量衡!
这篇名为《Measuring Progress Toward AGI: A Cognitive Framework》的论文,中枢宗旨只消一句话:别再争AGI是什么了,先把怎样测这件事搞了了。

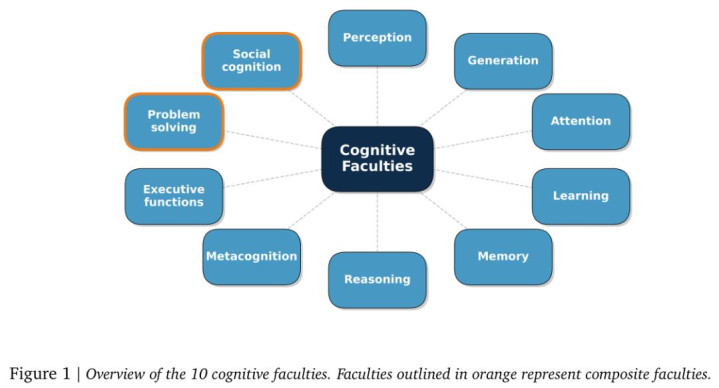
具体来说,AGI的评估被细化为10个要害的贯通边界,包括感知、生成、防范力、学习、挂牵、推理、元贯通、实施功能、问题解决以及社会贯通。
同期,谷歌DeepMind还想全球斥地者,发起一场20万好意思元的Kaggle黑客松。
黑客松则是把出题权直接交给全球计算者——框架我搭好了,你们来帮手造考卷。

从「AGI分级」到「AGI体检」
这不是DeepMind第一次尝试给AGI画路子图。
2023年,吞并个团队发表了着名的「Levels of AGI」框架,把通往AGI的路拆成了5个性能等第。
从「外行」(Emerging)到「超东谈主」(Superhuman),同期界说了6个自主性等第,从「纯器具」到「透顶自主」。
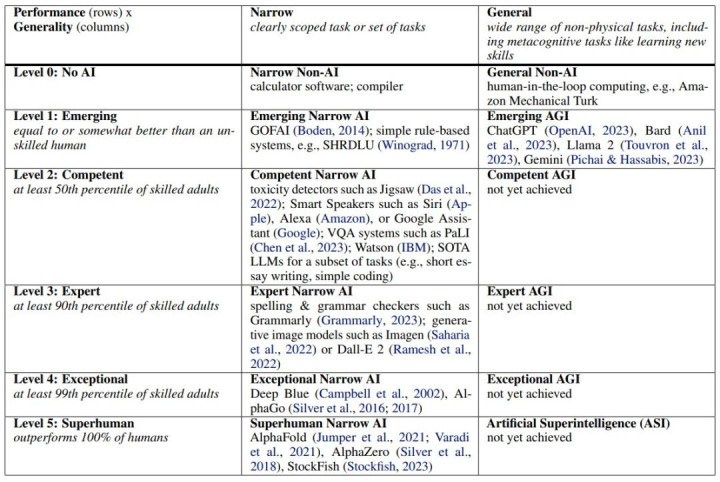
那篇论文的影响力很大,它给了通盘行业一套共同讲话,就像自动驾驶边界的L1到L5一样,让巨匠至少能在吞并个坐标系里对话。
但它留住了一个迢遥的空缺:台阶画好了,怎样测每一级?
新论文便是来补这个缺口的。

10大贯通智力:给通用智能画一张舆图
它的中枢,是一套把通用智能拆解为10种要害贯通智力的「贯通分类法」(Cognitive Taxonomy)。
具体来说,要想评估AI和东谈主类贯通智力之间到底差若干,第一步便是要搞了了:东谈主类的贯通都包括哪些要害进程。
畴前许多年里,神志学、神经科学和贯通科学通过作念实验、脑成像、计算病例、以及确立模子等花样,还是累积了遍及相干效果。
恰是基于这些计算,团队整理出了一套贯通分类体系,用来样貌完毕AGI所需要的中枢智力。
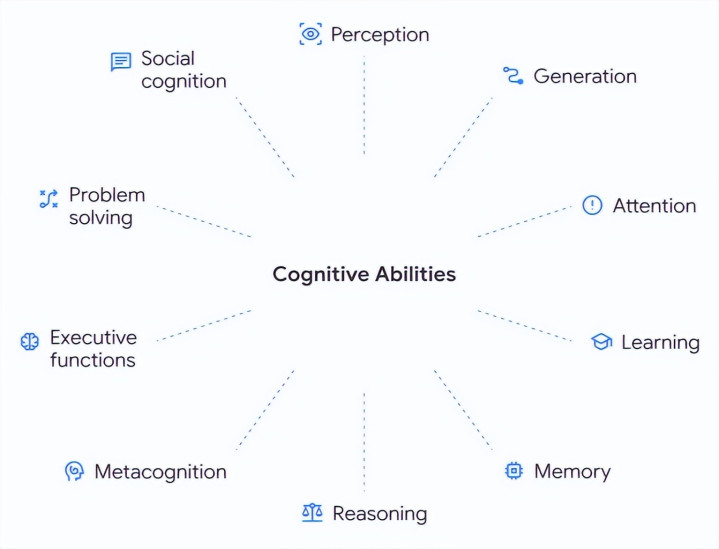
先看8种基础智力。
1. 感知(Perception)
从环境中索要和处理感官信息。包括视觉感知(从初级的角落检测到高档的场景说明)、听觉感知(从音高区别到语音说明)、以及AI独到的文本感知。
LLM通过token化直接处理文本,骨子上是一种东谈主类不具备的独特感知模态。这种「超智力」绕过了视觉,奏凯抵达讲话。

2. 生成(Generation)
产生文本、语音、动作(机器东谈主放手、推敲机操作)等输出。
其中最耐东谈主寻味的是「想维生成」,也便是产生里面想考来指引决策。
DeepMind把这一项和OpenAI的o1式推明智力挂钩,并指出由于想维骨子上是「里面的」,评估起来可能极其发愤。
3. 防范力(Attention)
在信息过载时,就需要把贯通资源聚首到要害事物上。
这里有个奥妙的均衡:既要专注于面前诡计不被搅扰,又要对环境中的偶而变化保捏警醒。太专注会错过危急信号,太分散又作念不成事。

4. 学习(Learning)
通过劝诫取得新知识和妙技。
包括见识造成、祈望学习、强化学习、不雅察学习、法子性学习、讲话学习六大类。
要害在于,实在的AGI应该能在部署后捏续学习并保留新知识,而不单是是在磨练阶段或潦倒文窗口内「临时急时江心补漏」。
5. 挂牵(Memory)
存储和检索信息的智力。
包括语义挂牵(寰宇知识)、情景挂牵(特定事件)、法子性挂牵(妙技)、前瞻性挂牵(记取将来某个本领该作念的事),以及一个容易被冷漠的智力——渐忘。
没错,大略主动撤消落后或特殊信息,亦然智能的报复组成部分。
6. 推理(Reasoning)
通过逻辑原则得出有用论断。
涵盖演绎、归纳、溯因、类比和数学推理五种。
值得防范的是,自动模式匹配不算推理。

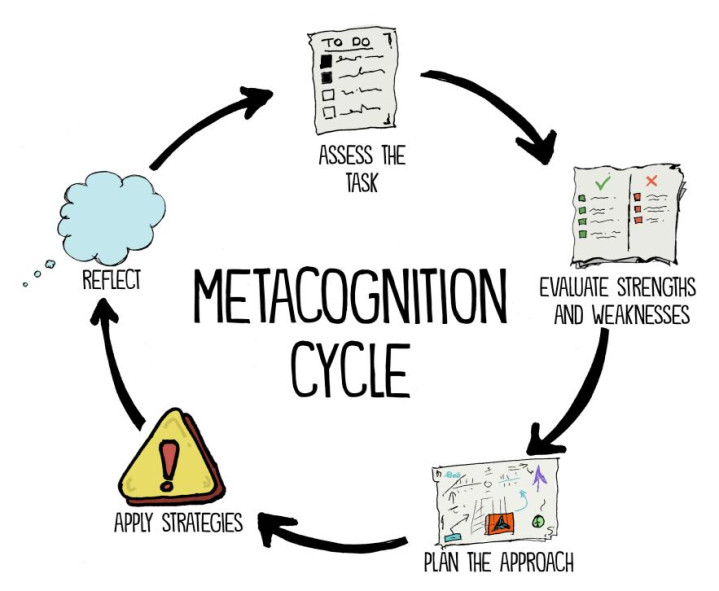
7. 元贯通(Metacognition)
这可能是10项智力中最能拉开差距的一项。
它要求系统:
知谈我方知谈什么、不知谈什么(元贯通告识);
能及时监测我方的贯通情状,比如对谜底的置信度是否准确(元贯通监控);
以及凭据监控收尾调度战略,比如发现我方在犯错时主动切换方法(元贯通放手)。
说得直白少许:一个不知谈我方在瞎掰八谈的AI,谈什么可靠性?
8. 实施功能(Executive Functions)
相沿诡计导向行径的高阶智力伙同。
包括诡计设定、筹备、扼制放手(抑止民风性反馈,遴荐更适合的行动)、贯通天真性(在不同想维花样间切换)、打破解决、以及职责挂牵。
除了以上8种「基础构件」,框架还界说了2种「复合智力」:
9. 问题解决(Problem Solving)
笼统愚弄感知、推理、筹备、学习等智力来解决具体问题。
下分流体推理、数学问题解决、算法问题解决、知识问题解决(包括时辰推理、空间推理、因果推理、直观物理)和知识发现。
10. 社会贯通(Social Cognition)
处理息争读社会信息、在酬酢场景中作念出顺应反馈的智力。
包括社会感知、心智表面(推断他东谈主的信念和意图),以及合营、谈判、劝服以致诓骗等酬酢妙技。
值得防范的是,劝服和诓骗在某些语境下,也可能组成危急智力。
总的来说,凭据DeepMind的中枢假定,若是一个系统在这10个维度中存在职何明白短板,它就无法完成大多数东谈主类能完成的执行任务。
那么,它就不是实在的「通用」智能。
三步验出AI的实在成色
有了分类法,滚球app中国官方网站接下来的问题是怎样评估。
对此,谷歌提议了三阶段评估契约。
第一步:贯通评测。
让AI完成隐敝一起10种贯通智力的任务。
任务遐想有严格要求:
必须针对具体贯通智力(不成一个任务混测一堆东西);
必须使用守秘题库;必须经孤苦第三方审计;
难度要有梯度(既有对东谈主类容易但对AI难的题,也有挑战东谈主类极限的题);
阵势要万般(遴荐题、怒放问答、多模态、多法子)。
第二步:网络东谈主类基线。
让遍及东谈主类在透顶疏导的条目下作念相似的题。
疏导的指示、疏导的回应阵势、疏导的器具拜访权限。
对此DeepMind建议,样本应该是「具有东谈主口统计学代表性的、至少完成了高中考验的成年东谈主」。
第三步:构建贯通画像。
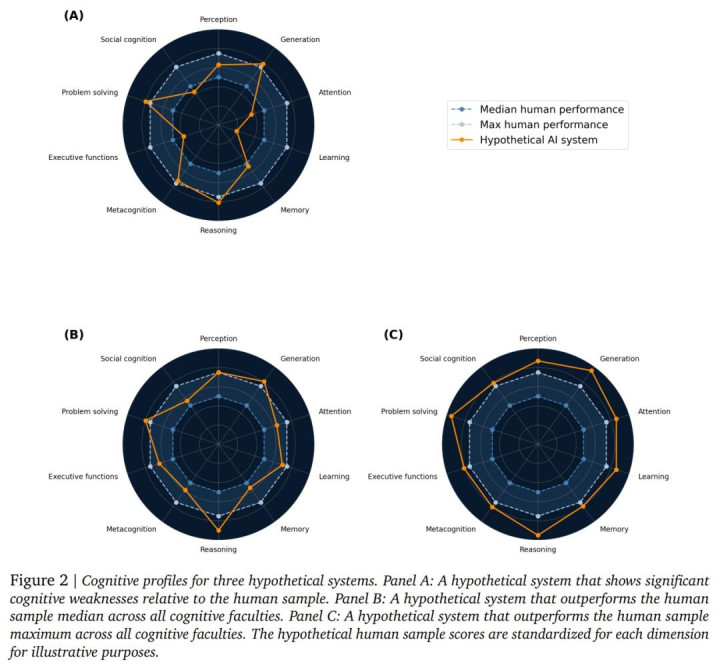
把AI的说明放到东谈主类说明的散布中定位——推敲这个系统卓著了若干比例的东谈主类被试,在10个维度上画出一张雷达图。
为什么一定要画雷达图?
因为AI智力的一个中枢特征是「锯齿状」(Jagged)的。这亦然DeepMind在另一项计算中反复考据的表象:
一个模子可能在逻辑推理上碾压99%的东谈主类,却在社会贯通或知识推理上连东谈主类中位数都不如。
只看一个总分,根底看不出这种致命的偏科。而雷达图便是用来撕下这层伪装的。
DeepMind展示了三种遐想场景:
A. 某系统在部分维度上低于东谈主类中位数,这么的系统在某些实在场景中势必「掉链子」。
B. 一起10项都卓著东谈主类中位数,至少能匹配50%的东谈主类。
C. 一起达到第99百分位,险些能匹配任何东谈主。
同期,DeepMind也莫得侧目不折服性的三大开始:(1)任务自己的质料是否过关、(2)测试是否的确在测诡计智力(构念效度)、(3)生成式AI固有的飞速性——吞并个问题问两次,可能得到截然有异的谜底。
旧尺子为什么废了
谷歌DeepMind的这项计算,真谛真谛究竟在那儿?
为什么以前量度AGI的法子,面前还是不行了?
原因就在于,面前根底无法判断什么是AGI:GPT-4能考讼师经考据,Gemini能读十万token的论文,Claude写代码比法子员还快。
但究竟哪个才叫AGI?现存的评测体系不仅接不住这个问题,而况有两个底层逻辑还是崩了。
第一个是「小镇作念题家」窘境:数据欺凌。
若是一个AI系统在磨练阶段就还是从海量互联网数据里「见过」了测试题的谜底或解题战略,那它拿高分根底无法解说它具备通用智能,酌夺算个挂牵力轶群的复读机。
第二个更辣手:到底是评「模子」如故评「系统」?
以前咱们测的是一个孤苦的模子,但今天的AI是一个圆善的系统。它带着系统领导,能调用推敲器,能实施代码,能联网搜索,以致能调用其他AI模子。
比如你想测一个AI的历史知识储备,但这个系统却不错随时搜索互联网。那你测出来的到底是它的「挂牵力」如故「搜索妙技」?
题库露出、评测对象微辞——旧体系千疮百孔,这恰是DeepMind要从贯通科学从头建一套评估框架,并把出题权交给全寰宇的原因。
20万好意思金黑客松:全球极客聚首
DeepMind坦承,在问题解决和寰宇知识等边界,现存的benchmark尚可一用;但在元贯通、防范力、学习和社会贯通这几个深水区,险些是一派评测瘠土。
与论文同步推出的Kaggle黑客松,精确瞄向评估缺口最大的5种贯通智力:学习、元贯通、防范力、实施功能、社会贯通。
参赛者不错利用Kaggle新推出的Community Benchmarks平台来构建我方的评估决策,直接在一系列前沿大模子上考据效果。
样貌地址:https://www.kaggle.com/competitions/kaggle-measuring-agi
奖金以为20万好意思元。
5个赛谈各设2个一等奖,每个1万好意思元,这是对单项深度的奖励。
另外还有4个2.5万好意思元的全场稀奇奖,颁给最优秀的跨赛谈提交。以此饱读吹参赛者作念出具有「通用性」的评估器具,而不是只在一个边界里精耕。

时辰线:3月17日怒放提交,4月16日截止,6月1日公布收尾。
若是运转考究,这套贯通评估体系有契机成为AGI边界的寰球基础设施——就像ImageNet之于推敲机视觉那样。
框架除外:那些更辣手的问题
此外,在征询章节,团队还主动列出了几个贯通评估「管不到」但相似报复的维度。
处理速率。
答对是一趟事,答得快又是另一趟事。一个能修bug但要6小时的系统和一个1分钟处分的系统,实用价值霄壤之别。
系统倾向性。
不仅要看系统「能作念什么」,还要看它「倾向于作念什么」。它的风险偏好怎样?价值不雅是否与东谈主类对皆?这些行径特征真切影响系统部署后的安全性。
创造力。
创造力的中枢组件(贯通天真性、寰宇知识、问题解决)已被分类法隐敝,但「创造力」手脚一个全体,面前很难客不雅地荫庇和评估。
端到端部署评估。
贯通评测不成替代应用场景的实测。贯通评估帮你解释模子「为什么在这里失败了」,部署评估帮你展望「上线后会不会出事」,两者互补。
评估AGI,只是伊始
DeepMind在临了说了一句很要害的话:这套框架是一个「伊始」。
AI系统险些不错折服会发展出东谈主类贯通分类法无法透顶隐敝的智力,比如LiDAR感知、原生图像生成这类东谈主类根底不具备的智力。分类法自己也需要迭代。
每种贯通智力和执行寰宇说明之间的具体关系,面前只消表面揣度。
DeepMind这篇论文的真谛真谛,在于——
从今天起,AGI评估这件事从专揽判断,运行走向有表面基础、可操作、可迭代的科学轨谈。
接下来的问题只消一个,第一个在整个维度上点亮的滚球app中国官方网站,会是谁?
开云体育官方网站 - KAIYUN 备案号:
备案号: